Catherine Weaver
Using advanced model-based controls, machine learning, and reinforcement learning to control the world around us.
Contact
catherine22@berkeley.eduEnd-to-end Learning Projects

Sparse Reward Reinforcement Learning (Project Website)
Skill-Critic: Refining Learned Skills for Hierarchical Reinforcement Learning
Our Skill-Critic algorithm optimizes both the low and high-level policies of a hierarchial agent, AND these policies are initialized and regularized by a latent space learned from offline demonstrations to guide the joint policy optimization. We validate our approach in multiple sparse RL environments, including a new sparse reward autonomous racing task in Gran Turismo Sport. The experiments show that Skill-Critic's low-level policy fine-tuning and demonstration-guided regularization are essential for optimal performance.

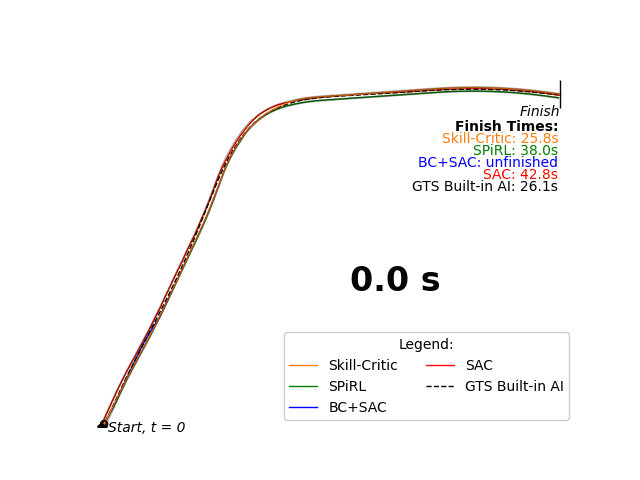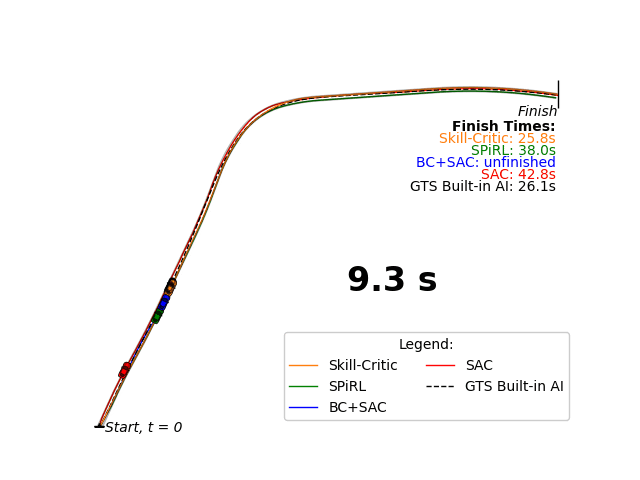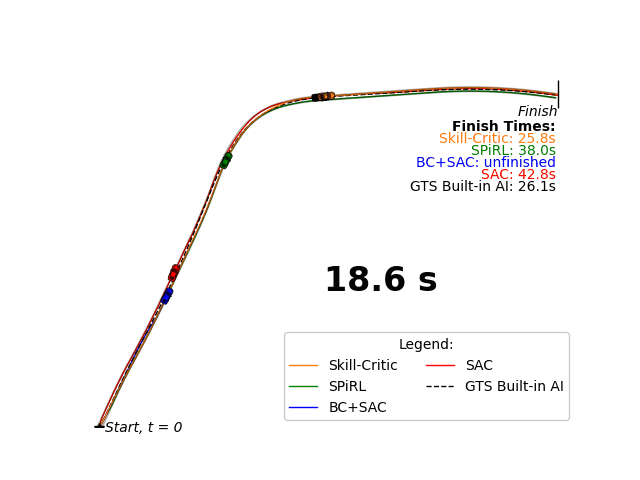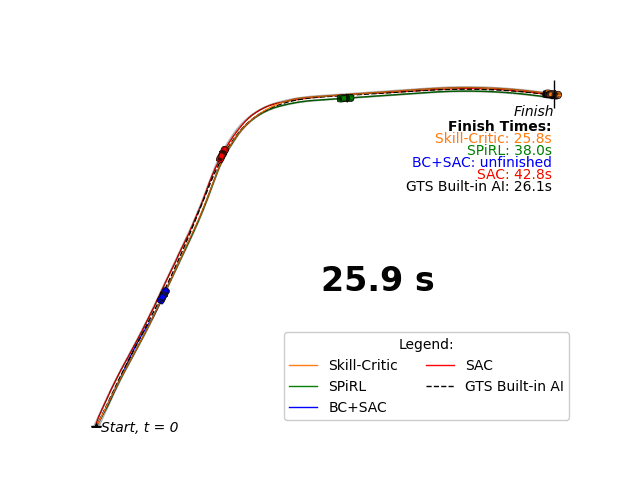
Highlight of my Contributions:
- Derived the theoretical framework that extended the discrete options-based semi-MDP framework to encompass skills, which employ a continuous latent space and fixed time horizons
- Extended the skill-based semi-MDP formulation to a framework of two augmented MDPs so that the high-level and low-level policies could be optimized in parallel
- Theoretically justified the use of inter-related Q functions to improve performance of the low-level policy by incorporating the value assigned by high-level skills
- Primary writer of the manuscript and any rebuttals where I refined and defended the research
Related Publications:
- Hao, C.*, Weaver, C.* (*Equal Contribution), Tang, C., Kawamoto, K., Tomizuka, M. Zhan, W. “Skill-Critic: Refining Learned Skills for Reinforcement Learning”, IEEE Robotics and Automation Letters 2023. Awaiting Review. Available at: sites.google.com/view/skill-critic. Related Project: link
Visit the 🔗 Project Website for the code and manuscript, videos, and more information about this project.
Imitation Learning from Human Demonstrations (Project Website)
BeTAIL: Behavior Transformer Adversarial Imitation Learning from Human Racing Gameplay
Recent successes in autonomous racing leverage reinforcement learning; however, imitation learning is a promising alternative for learning from human demonstrations without requiring hand-designed rewards. However, learning a racing strategy from human demonstrations is difficult due to the unknown decision-making process and complex environment. Sequence modeling is a powerful non-Markovian approach, but offline learning struggles to overcome distribution shifts and adapt to new environments. Adversarial Imitation Learning (AIL) can mitigate this effect; however, AIL can be sample inefficient and may fail to model human decision-making with Markovian policies. To capture the benefits of both approaches, we propose BeT-AIL: Behavior Transformer-Assisted Adversarial Imitation Learning. BeT-AIL employs BeT to learn a non-Markovian policy from human demonstrations, and an added residual policy corrects BeT policy errors. The residual policy is trained with AIL to match the state occupancy in online rollouts with the state occupancy of demonstrations. We test BeT-AIL on three challenges with expert-level demonstrations from real human gameplay in the high-fidelity racing simulator Gran Turismo Sport. First, the BeT and residual policy are trained on the same demonstrations and track, and BeT-AIL outperforms standalone BeT and AIL. Then, the BeT policy is pretrained on one or more tracks, and BeT-AIL fine-tunes the policy on unseen tracks with limited demonstrations. In all three challenges, BeT-AIL reduces the necessary environment interactions and improves racing performance or stability, even when the BeT is pretrained on different tracks.


Highlight of my Contributions:
- Full development of the BeTAIL algorithm, including decision to use the Behavior Transformer, residual policy, and adversarial imitation learning
- Adaptation of existing code-bases to include residual policy, multiple different types of regularization on the discriminator network, and extended features in PPO and SAC algorithms
- Code implementation of gym environment and calculation of track-related state features for both demonstrations and environment
- Experiment design and execution, including design of configuration files to handle all baseline and hyperparameter choices
- Currently finalizing paper manuscript for submission as corresponding author
Related Publications:
- Weaver, C., Tang, C., Hao, C., Kawamoto, K., Tomizuka, M. Zhan, W. “BeTAIL: Behavior Transformer Adversarial Imitation Learning from Human Racing Gameplay.” IEEE Robotics and Automation Letters. Awaiting Review. Available at: sites.google.com/berkeley.edu/betail Related Project: link
Visit the 🔗 Project Website for the code and manuscript, videos, and more information about this project.
Learning with Human Feedback and Preferences
Racing Metric: Systematic Trajectory Evaluation from Human Feedback and Preferences
This is an ongoing research project in which we plan to investigate how we can learn racing metrics from human feedback. We will explore how to learn metrics for evaluating racing performance from human feedback, so that the learned metrics are consistent with human values from various aspects (e.g., sportsmanship), which are highly difficult to model with manually designed reward/cost functions. The learned metrics can serve as reward functions for training RL policies, cost functions for model-based optimal controller, and evaluation metrics for a principled and fair benchmark of all categories of autonomous racing algorithms.
We are inspired by the recent success of reinforcement learning from human preferences (RLHP). RLHP learns the reward function from human preferences during RL training. We aim to adapt this approach to develop a comprehensive metric that will be applied to already trained agents to test how well the decent quality agents align with human values. This problem is known as Value Alignment Verification, and has only recently been studied on simplified cases, often with restrictive assumptions like known human reward functions. By leveraging the strengths of human preferences, we aim to extend Value Alignment Verification to the complicated multi-agent racing problem.
Ongoing areas of invesitigation:
- Trajectory filtering and identification of important moments
- Reinforcement learning from human preferences
- Preference transformer, which uses sequence modeling to model non-Markovian human preferences
Highlight of my Contributions:
- Collection of human demonstrations and data analysis and filering to examine important moments
- Creation of diverse AI agents that exhibit different types of sportsmanship behavior
- Development of a system to identify important moments in agent and demonstrated trajectories that should be labeled with a preference
- Setup of a computer system to display trajectories to human experts and collect their preferences between trajectories
- Development of a racing metric that takes a trajectory as input and outputs how well the trajectory aligns with human values and preferences